
比如一个学校的学生,大概率是会出现重名的学生,
这个时候比如我们想知道张三同学的成绩,获得的结果可能就不准确,
因为可能一班二班都有张三,这个时候我们再加个条件,一班的张三同学的成绩,这个时候大概率就能保证结果的唯一性,
如果这个班级又有两个张三同学,我们可以再加条件,比如座次,身高,年龄等等条件就能保证唯一性了
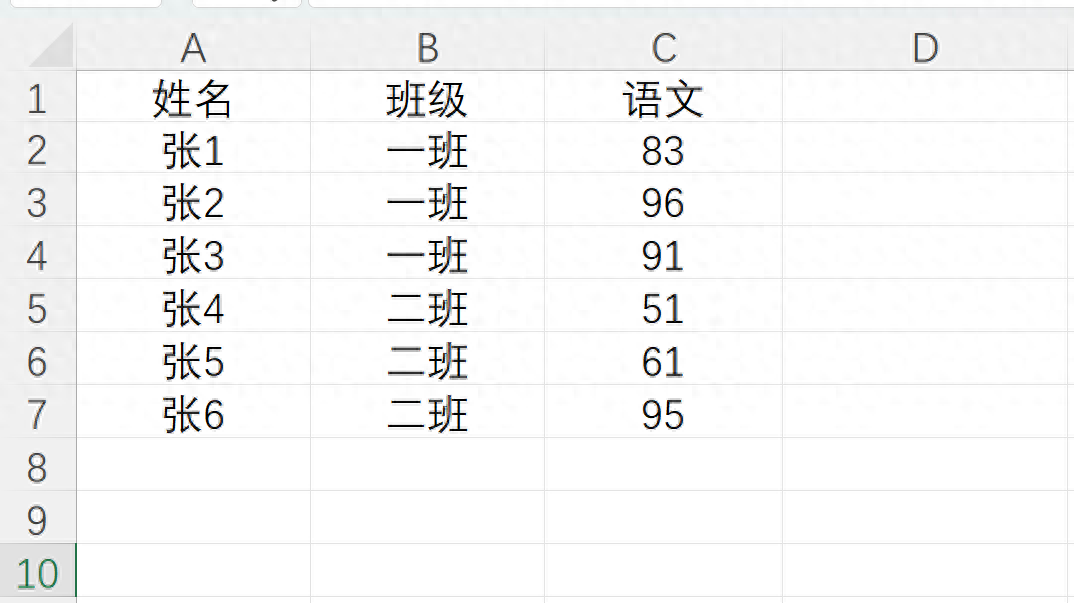
| 姓名 | 班级 | 语文 |
| 张1 | 一班 | 83 |
| 张2 | 一班 | 96 |
| 张3 | 一班 | 91 |
| 张1 | 二班 | 51 |
| 张2 | 二班 | 61 |
| 张3 | 二班 | 95 |
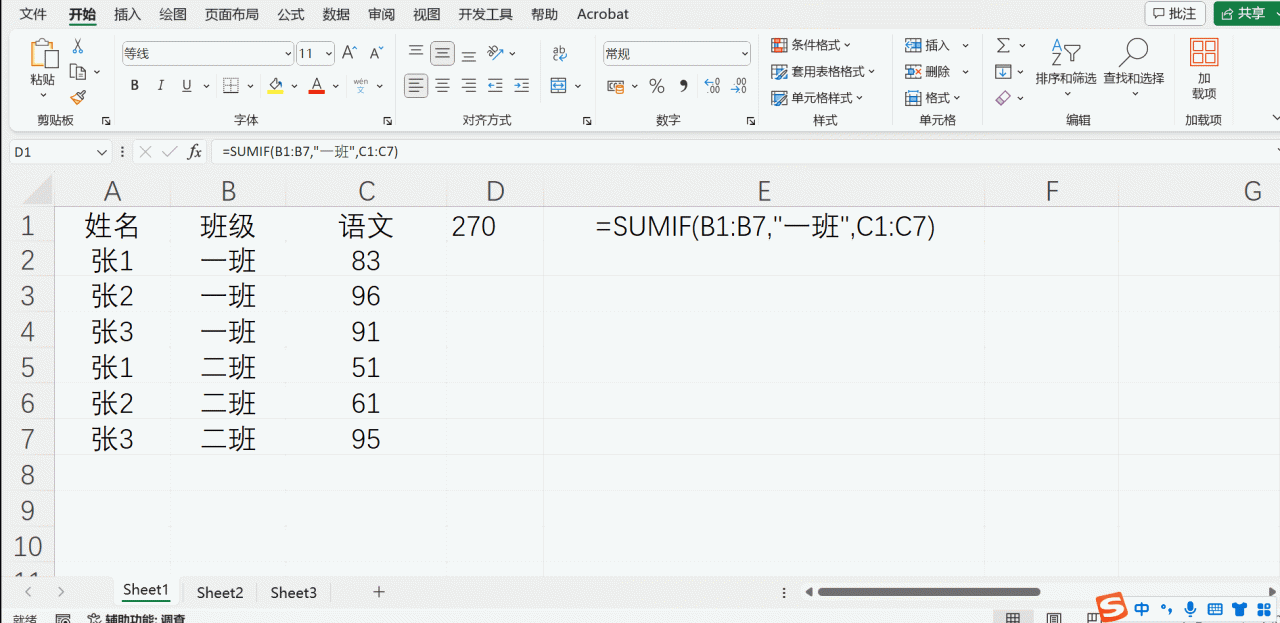
比如我们想求一班张1的语文成绩之和:上面数据一班张1只有1个,求和的结果其实就是一班张1的成绩,比如某个省市叫张三的人名,可能就不止一个了,要理解函数的适用性。
SUMIFS(sum_range, criteria_range1, criteria1, [criteria_range2, criteria2], ...)
sum_range:是求和的区域,在上面的数据表格中,代表的就是语文成绩所在的列
criteria_range1:是包含第一个条件的区域,比如我们说一班张三,第一个条件是班级所在的列,第二个条件是人名所在的列,criteria_range1就是班级所在的列
criteria1:是第一个条件,也就是一班
criteria_range2:是包含第二个条件的区域,比如我们说一班张三,第一个条件是班级所在的列,第二个条件是人名所在的列,criteria_range2就是人名所在的列
criteria2:是第一个条件,也就是张三
...
另外注意criteria_range1, criteria1是成对出现的,就是条件和包含条件的区域
两个条件,三个条件或者更多的条件对criteria_range2, criteria2...
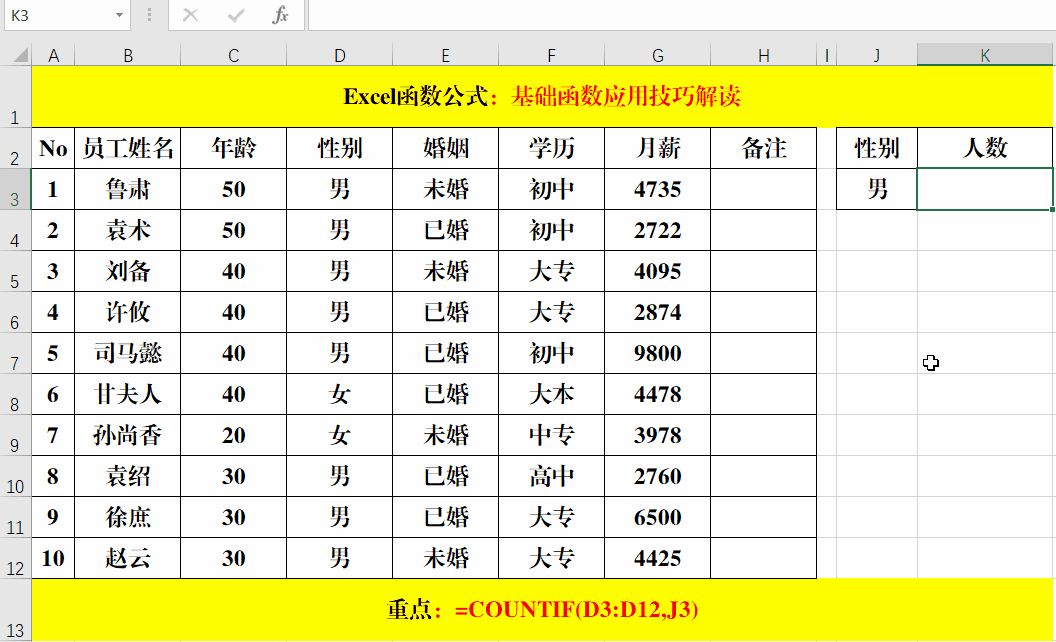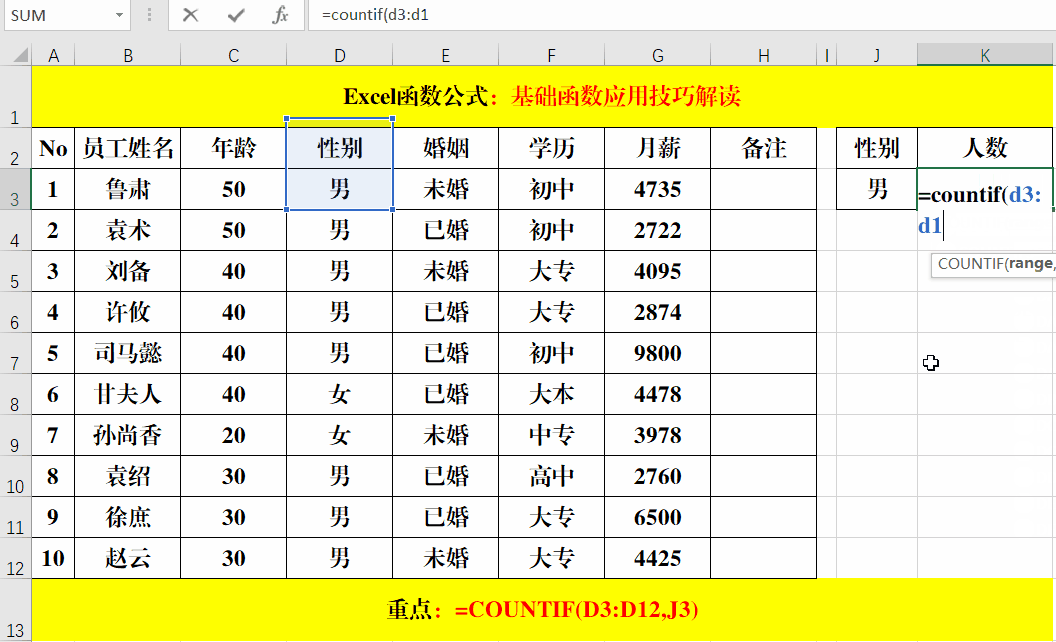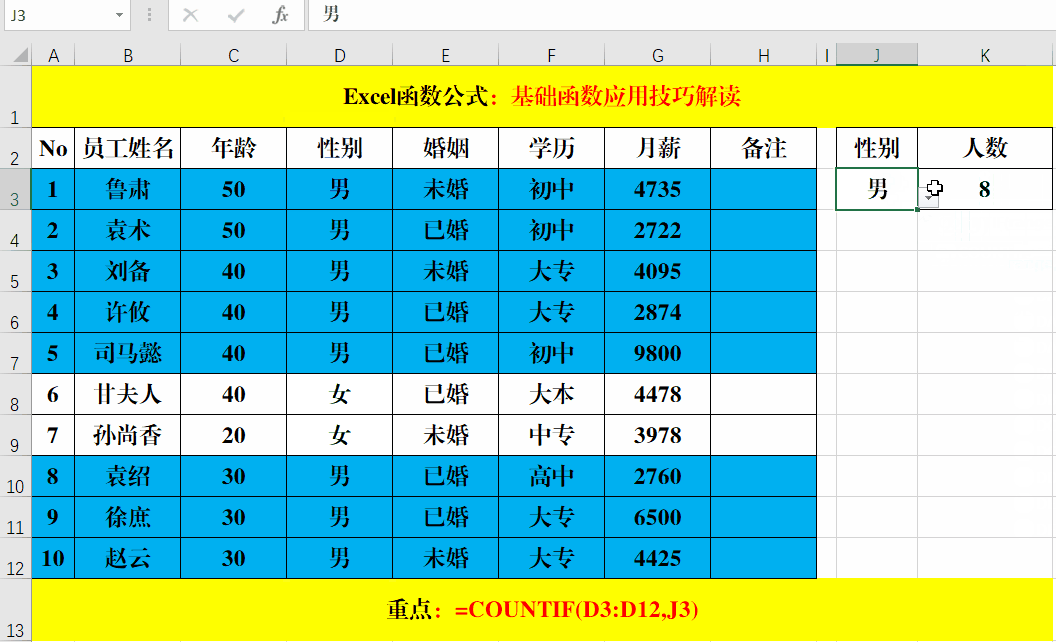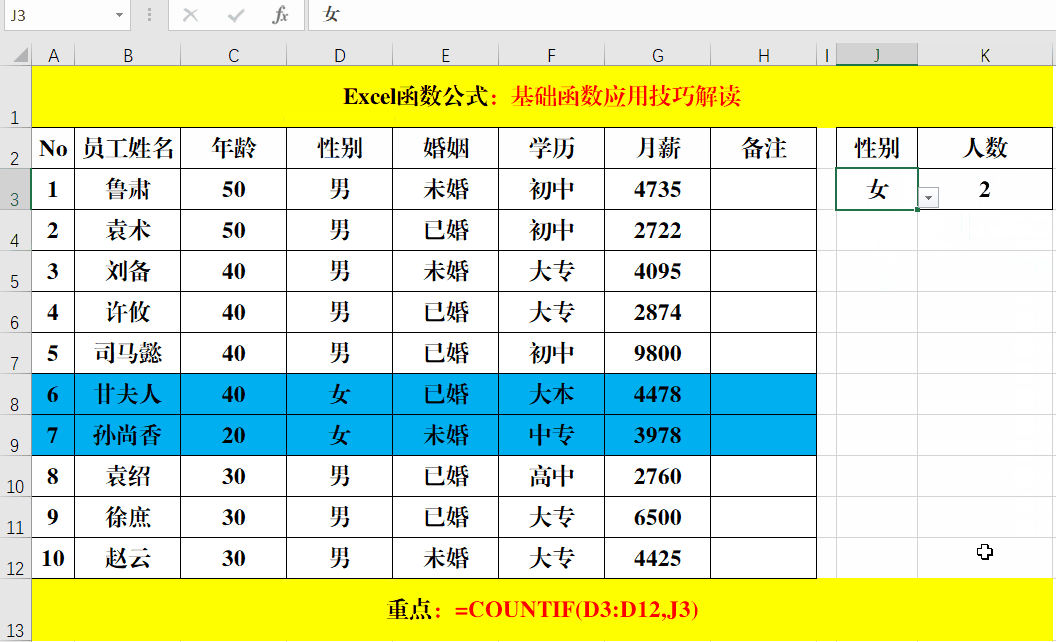
我们看一下sumifs函数的用法




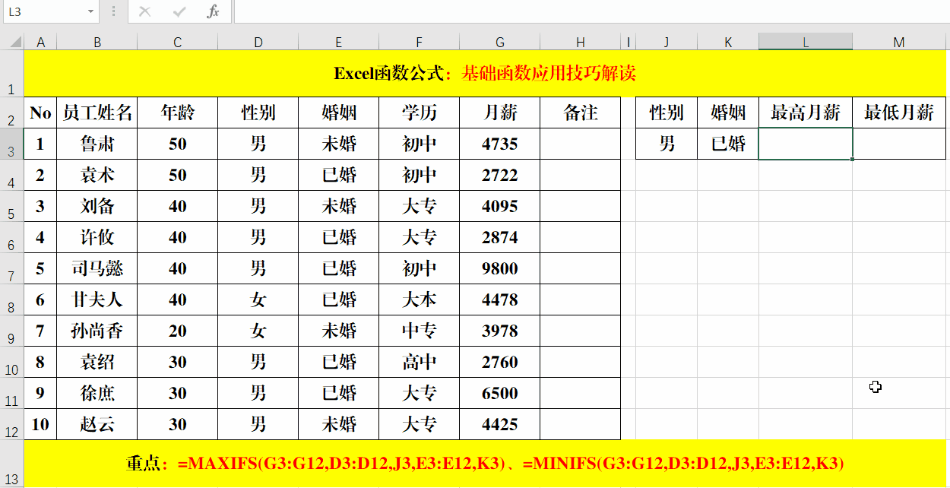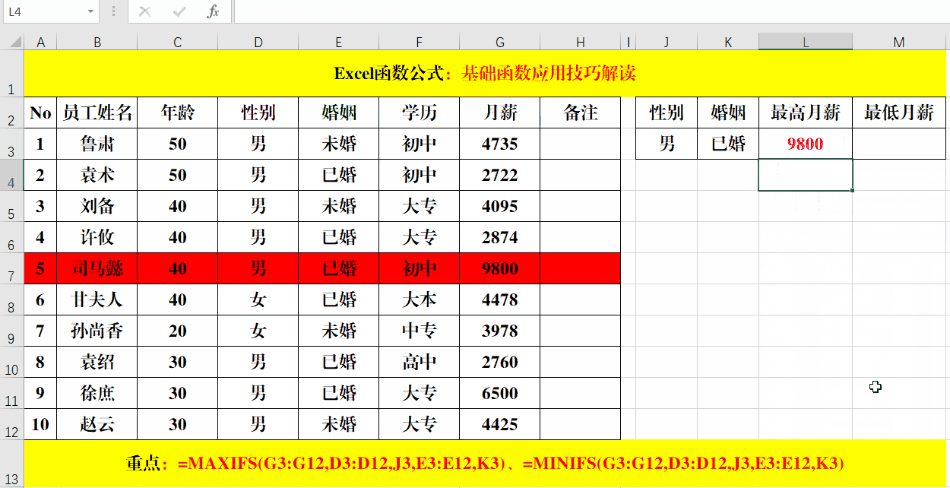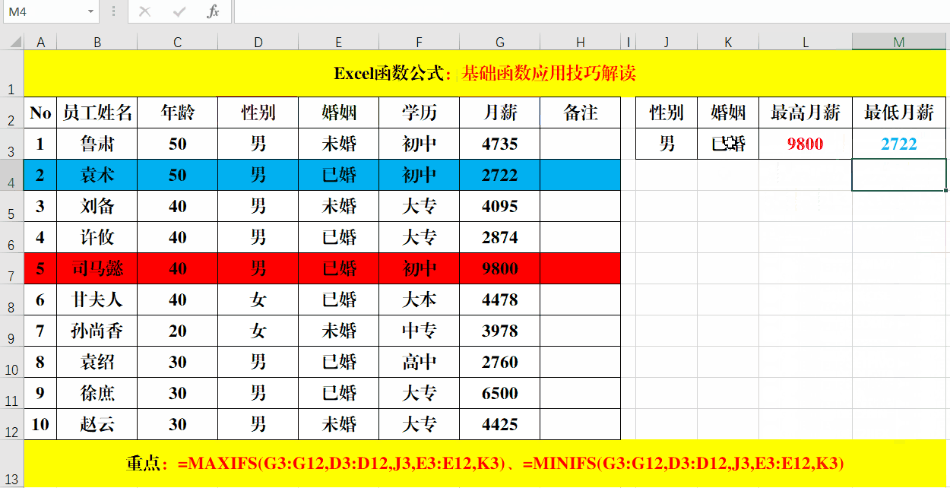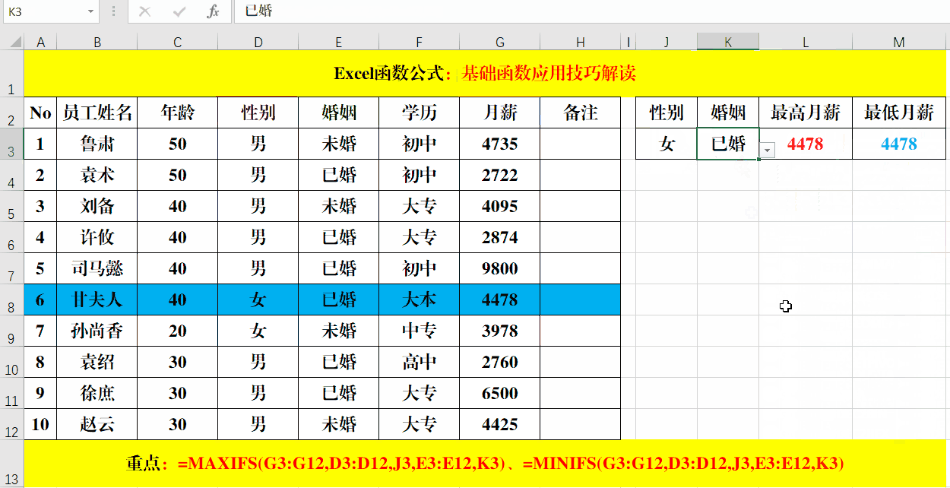
评论 (0)