
在数据处理过程中,我们常常会遇到需要统计不重复数据数量的情况。例如,在一组产品品种数据中,A列包含了多个重复的品种名称,而我们想要准确统计出实际不同品种的数量,此时就需要先去除重复值再进行计数。在高版本Excel中,借助UNIQUE函数和COUNTA函数的组合,能够轻松实现这一目标。
一、函数解析
UNIQUE函数:这是Excel高版本中新加入的强大函数,专门用于从数据区域中提取不重复的值。其语法为UNIQUE(array,[by_col],[exactly_once])。在我们的例子中,使用UNIQUE(A2:A11),其中A2:A11是需要处理的数据区域,即我们要从A列第2行到第11行的品种数据中提取不重复的品种名称。函数会自动识别并去除重复项,仅保留唯一值。
COUNTA函数:该函数用于计算区域内非空单元格的数量。其语法为COUNTA(value1,[value2,...])。在我们的公式=COUNTA(UNIQUE(A2:A11))中,将UNIQUE函数提取出的不重复值区域作为COUNTA函数的参数。COUNTA函数会对这个不重复值区域进行计数,从而得出实际不同品种的数量。
二、操作步骤
- 准备数据:确保数据已完整录入Excel工作表,且需要统计的包含重复值的数据列(如A列品种数据)清晰明确。
- 输入公式:在需要得出统计结果的单元格中,输入公式
=COUNTA(UNIQUE(A2:A11))。这里的A2:A11需根据实际数据所在区域进行调整,如果数据是从A列第3行到第20行,则公式应改为=COUNTA(UNIQUE(A3:A20))。 - 得出结果:输入公式后,按下回车键,Excel会立即计算并在该单元格中显示出去除重复值后的品种数量。
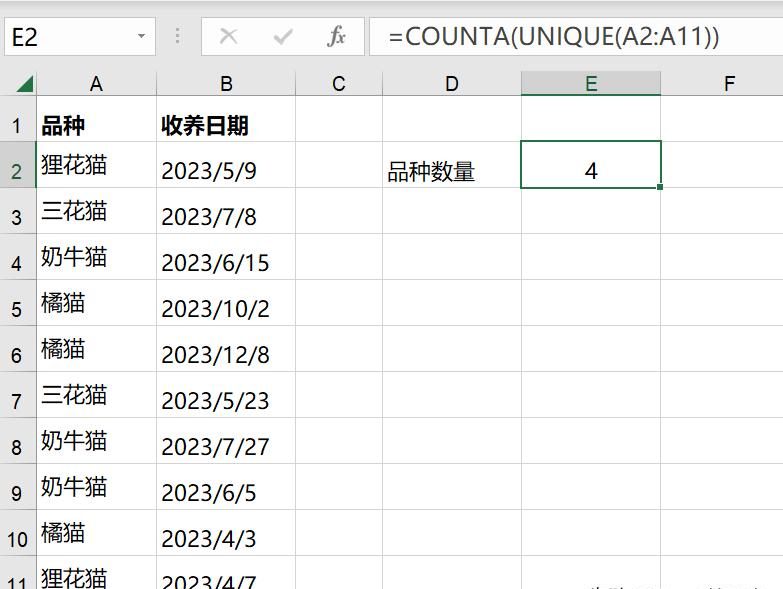
通过这种方式,利用Excel高版本中的UNIQUE函数和COUNTA函数的组合,能够快速、准确地完成去除重复值计数的任务,大大提高数据处理的效率和准确性,为数据分析工作提供有力支持。


评论 (0)