
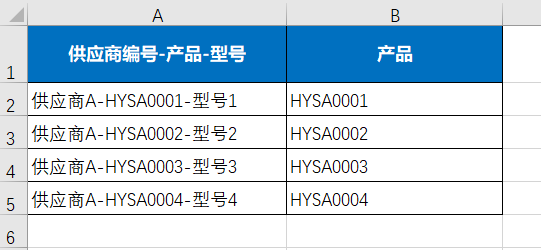
在Excel的数据处理场景中,我们常常会碰到需要从复杂的数据布局里提取特定信息的情况。就像下面这张值班表(如下图所示),我们的目标是从左侧的表格中提取出不重复的员工名单。这张表格的结构有些特殊,A列和C列记录着姓名信息,B列和D列则是对应的值班电话信息。面对这样不连续的区域数据,借助Excel的函数组合,我们可以轻松达成目标。
观察表格,A2:A7单元格区域和C2:C7单元格区域分别存放着不同的员工姓名数据,它们在表格中处于不相邻的位置。为了提取出这些区域中的不重复员工名单,我们在F2单元格输入公式 “=UNIQUE(VSTACK(A2:A7,C2:C7))” ,按下回车键后,原本分散在A列和C列的员工姓名,经过函数的处理,就会以不重复的形式呈现在 F 列中。
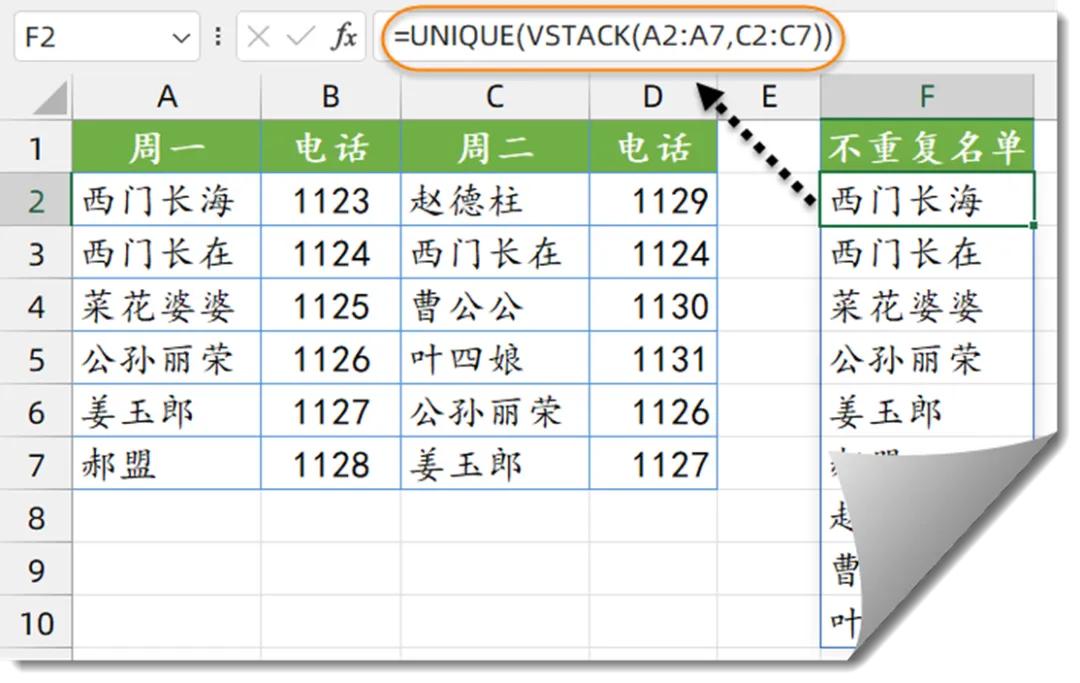
这个公式的实现主要依赖于 VSTACK函数和UNIQUE函数的协同工作。首先,VSTACK函数 “VSTACK(A2:A7,C2:C7)” 发挥作用。VSTACK函数的功能是将多个数组合并成一个新数组,在这里,它把A2:A7和C2:C7这两个不相邻的区域数据合并成了一列。也就是说,它会按照顺序将 A 列中的姓名数据和C列中的姓名数据依次堆叠起来,形成一个新的、连续的姓名数据列。
接着,UNIQUE函数 “UNIQUE(VSTACK(A2:A7,C2:C7))” 登场。UNIQUE函数的作用是从给定的数据中提取出不重复的值。当它对VSTACK函数合并后的那一列姓名数据进行处理时,会自动去除其中重复的姓名,只保留唯一的员工姓名记录。这样,最终在F2单元格及以下的单元格中,就会显示出从A列和C列不连续区域提取出的不重复员工名单。
通过掌握这个公式的用法,当我们在处理类似的需要从不连续区域提取不重复数据的任务时,无论是处理员工名单,还是其他类型的数据,都能够快速、准确地获取到所需的信息,大大提高Excel数据处理的效率。这让我们在面对复杂的数据布局时,也能轻松应对,更好地进行数据分析和管理工作。

评论 (0)