
在数据处理的日常工作中,从文本里提取特定数值一直是个高频且棘手的任务。过去,完成这项工作常常让人大费周章,可在2025年的今天,这已不再是难以跨越的大山。接下来,就为大家详细剖析如何轻松实现文本中数值的提取。
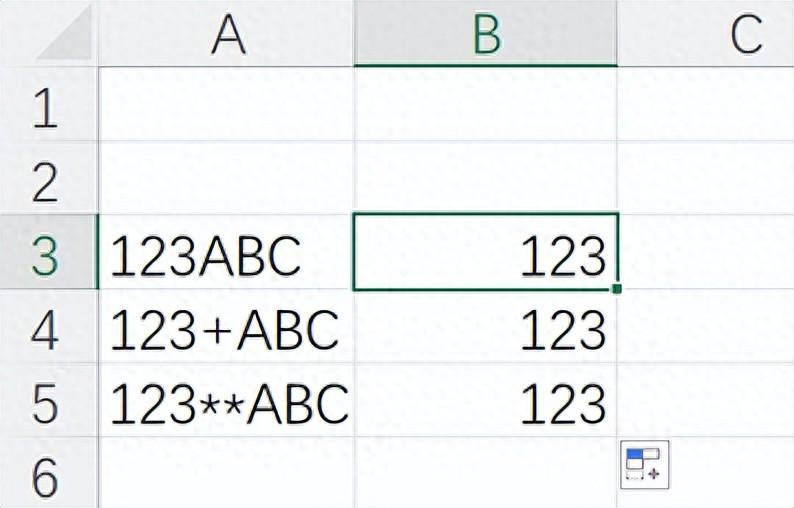
假设我们面对这样一组文本数据,如下图所示,需要从中精准提取出 “kg” 合计和 “块” 合计。乍一听,是不是觉得有些无从下手?别担心,接下来就为大家一步步拆解解决方法。
一、回顾老思路解法
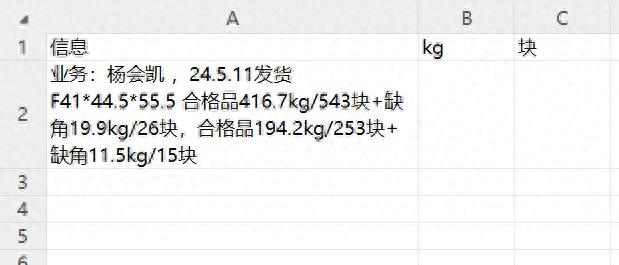
1、提取 “kg” 明细:以往采用的一种复杂方法是使用公式 “=REDUCE ("",TEXTSPLIT (A2,"kg"),LAMBDA (x,y,VSTACK (x,-IFNA (LOOKUP (1,-RIGHT (y,ROW (1:16))),)))” 。这里涉及到多个函数的嵌套运用,REDUCE 函数用于在一系列值上执行累积计算,TEXTSPLIT函数负责根据指定的分隔符 “kg” 拆分文本字符串,LAMBDA函数则定义了一个匿名函数,在这个函数中,通过VSTACK函数将每次提取的数值堆叠起来,同时利用LOOKUP函数和RIGHT函数从拆分后的文本片段中提取数值,并通过 IFNA函数处理可能出现的错误值。经过这样层层嵌套的运算,才能得到 “kg” 明细的提取结果。虽然最终能得出正确结果,但整个过程相当复杂,让人看得眼花缭乱。
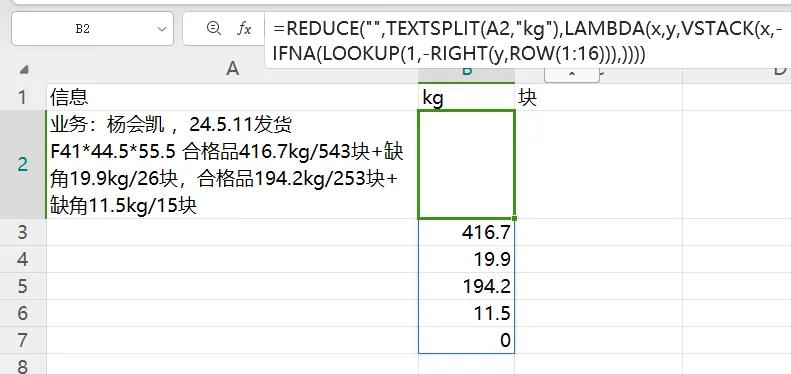
2、计算 “kg” 合计:为了得到 “kg” 的合计值,还需要进一步调整公式,将上述公式中的VSTACK部分换成 “+” 号,即 “=REDUCE (0, TEXTSPLIT (A2,"kg"), LAMBDA (x,y,x-IFNA (LOOKUP (1,-RIGHT (y,ROW (1:16))),)) )” 。
这种写法依然需要对多个函数的逻辑和参数有深入理解,对于普通用户来说,理解和操作难度极大,稍不注意就可能出错。
二、WPS简单写法登场
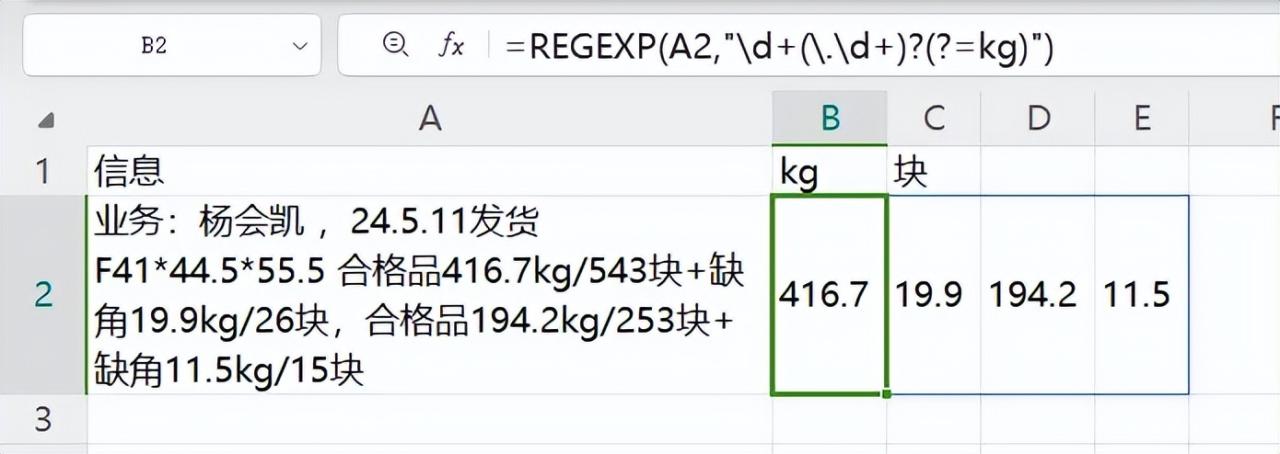
1、提取后面是 “kg” 的数值:进入2025年,借助WPS强大的函数功能,提取数值变得轻松许多。使用公式 “=REGEXP (A2,"\d+(.\d+)?(?=kg)")” 就能轻松搞定。这里的 REGEXP 函数是一个正则表达式函数,它可以按照特定的模式匹配文本中的内容。在这个公式中,“\d+(.\d+)?(?=kg)” 是正则表达式模式,“\d+” 表示匹配一个或多个数字,“(.\d+)? ” 表示匹配一个可选的小数部分(小数点后面跟着一个或多个数字),“(?=kg)” 是一个正向预查断言,表示匹配的数字后面必须紧跟着 “kg”。通过这样简洁的一个公式,就能精准提取出文本中后面跟着 “kg” 的数值,相比老思路,简洁明了许多。
2、转数字并求和:提取出数值后,如果需要计算这些数值的总和,也非常简单。只需使用公式 “=SUM (--REGEXP ($A2,"\d+(.\d+)?(?="&B1&")"))” 。这里通过在REGEXP函数前加上两个负号 “--”,将提取出的文本型数值转换为数值型,然后利用SUM函数对这些数值进行求和。其中,“A2”表示要处理的文本数据所在单元格,“B$1” 表示条件(如 “kg” 或 “块”)所在单元格,通过这种方式,可以灵活地根据不同条件提取并求和相应的数值。
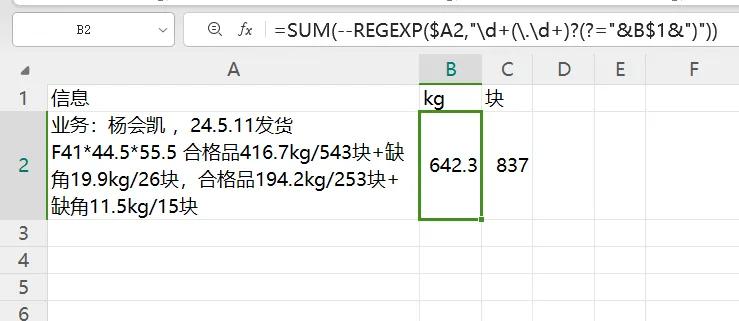
无论是处理 “kg” 合计还是 “块” 合计等文本数值提取需求,利用新的函数和方法,都能让数据处理工作变得高效且轻松。掌握这些技巧,能极大提升我们的数据处理能力,为工作和学习带来更多便利。赶紧动手试试吧,体验数据处理的全新变革!


评论 (0)