
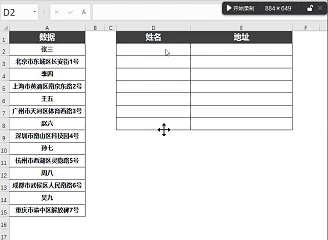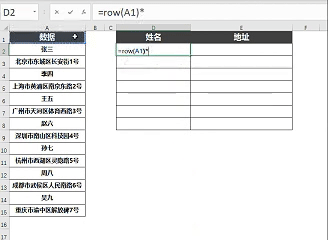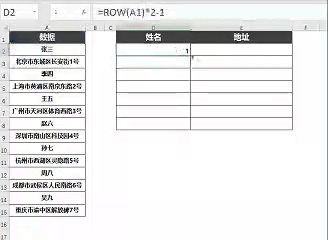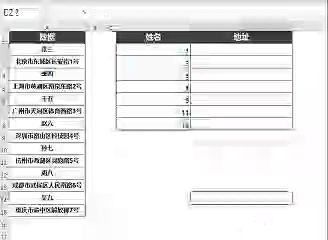
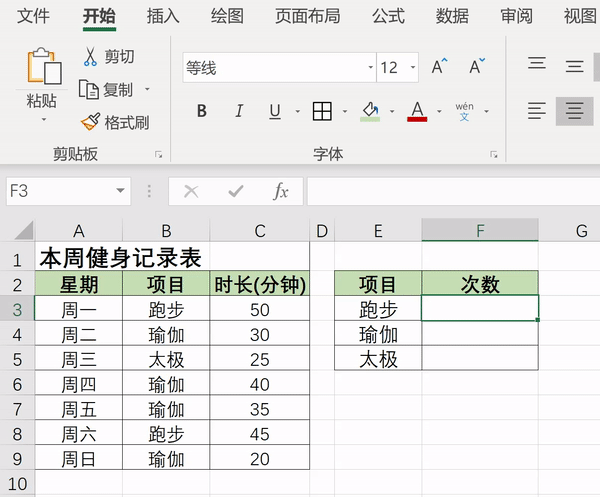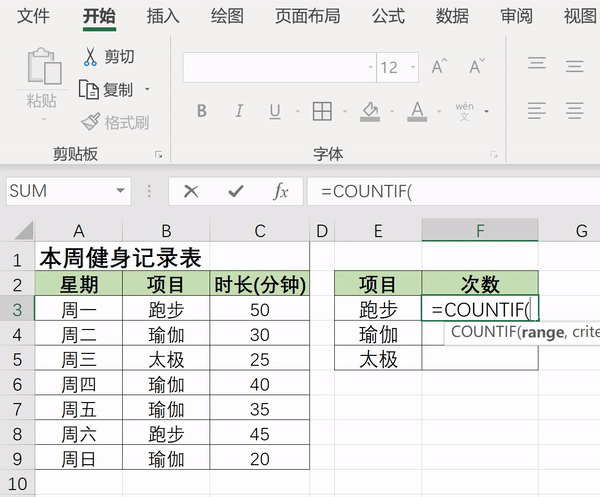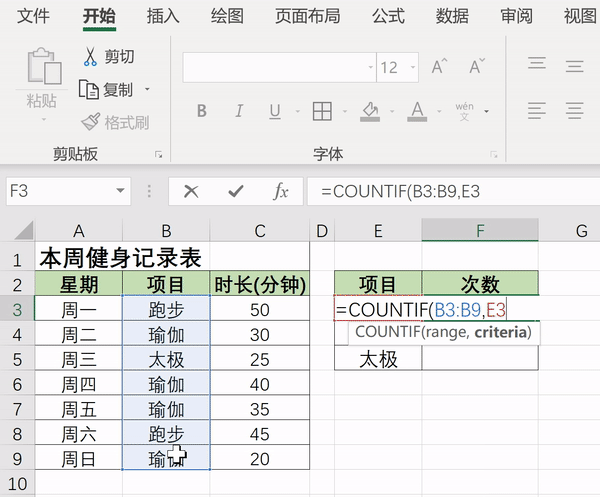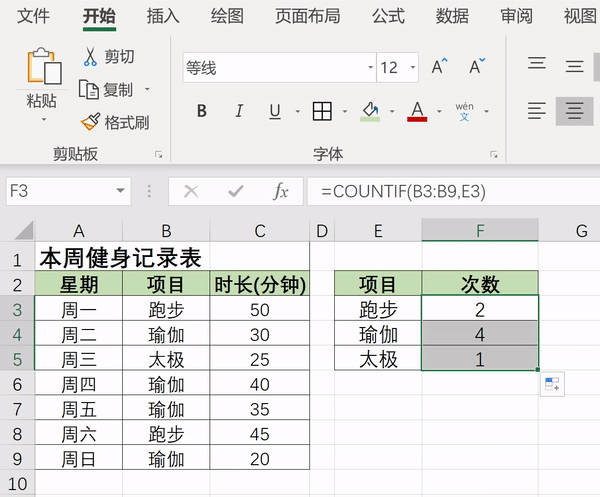
如图所示:
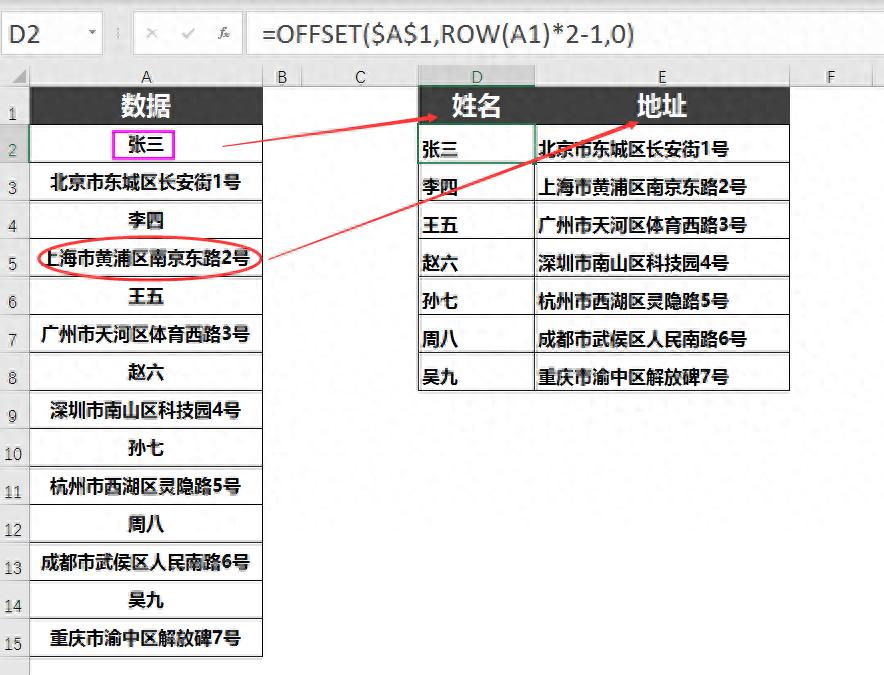
我们的数据源是一个名字和地址交叉排列的数据区。
现在,我们需要将这些名字和地址隔行提取出来。
这时,OFFSET函数就能派上大用场。
首先,我们来看一下如何编写这个公式。
OFFSET函数的基本语法包括四个参数:
OFFSET(基准、偏移行数、偏移列数,返回的区域大小)。
(1)设置偏移行数:这是实现隔行提取的关键。
如果我们以A1为基准,向下偏移1行就能取到“张三”的名字,向下偏移3行取到“李四”的名字,依此类推。
为了实现这样的数字序列(1、3、5...),我们可以使用ROW函数。
输入=ROW(A1)*2-1
这样当我们向下拖动公式时,它就会依次生成1、3、5、7...这样的数字序列。
(2)利用OFFSET函数编写公式:
输入公式:=OFFSET($A$1,ROW(A1)*2-1,0)

第一参数$A$1:这里选择了A1单元格作为偏移的起始点,并通过使用绝对引用(即在行号和列号前加上$符号)来锁定它。
这样做的目的是确保在公式被复制到其他单元格时,起始点不会发生变化。
换句话说,无论公式被移动到哪里,它始终会从A1单元格开始偏移。
第二参数ROW(A1)*2-1:是偏移的行数
第三参数0:是偏移的列数,这里只有一列数据,我们不需要偏移列,所以偏移值为0。
这样,我们就能隔行提取出所有的名字了。
(3)提取地址
同样的原理,我们也可以用来提取地址。
只需稍微调整OFFSET函数的第二个参数(偏移行数),将ROW(A1)*2-1改为ROW(A1)*2(因为地址需要偏移两行才能得到)。
输入公式:
=OFFSET($A$1,ROW(A1)*2,0)

其他参数保持不变,然后向下填充公式即可。
总结:
隔行提取数据的关键在于OFFSET函数的第二个参数——偏移的行数。
通过这个参数,我们可以灵活地控制提取数据的行间隔。
如果以后需要隔两行、三行甚至四行提取数据,我们也可以按照这个思路进行调整。
希望这个技巧能对大家的工作有所帮助。



评论 (0)