
如何在海量数据中一键剔除重复,精准计算唯一值数量?COUNTA,COUNTIF与COUNTIFS:数据清洗与统计的得力助手!"
场景一:统计单列中不重复名字的个数
面对单列数据,这种情况比较简单:
(1)先把源数据复制出一份,现选择"数据”---删除重复项,删除重复项对话框中列前的勾打上,再按确定。
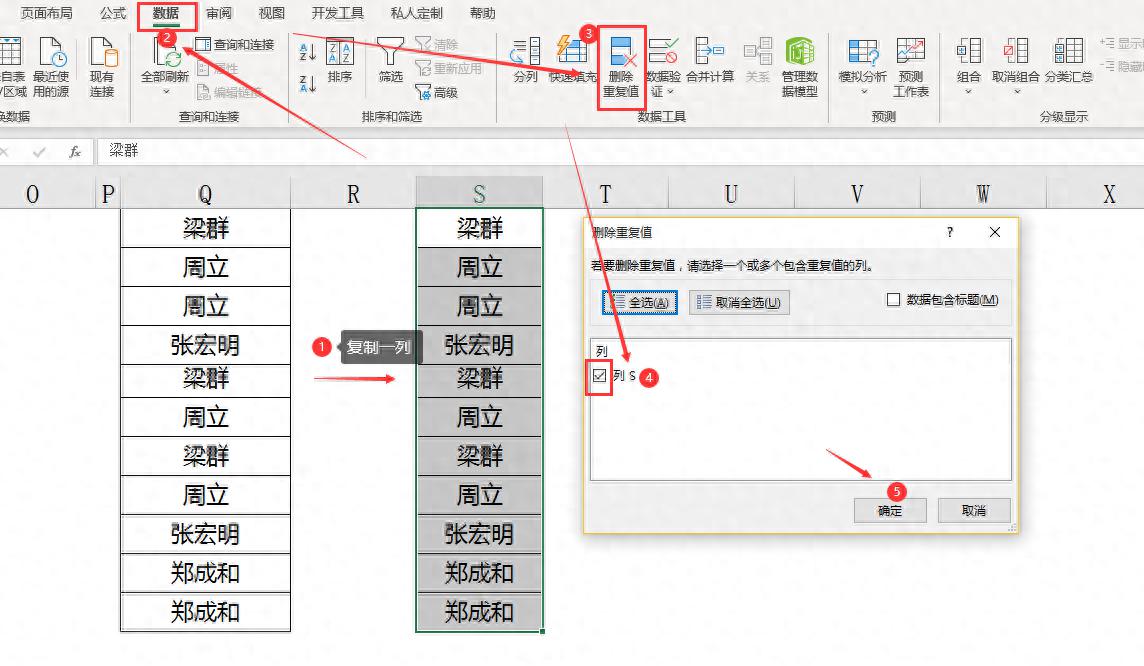
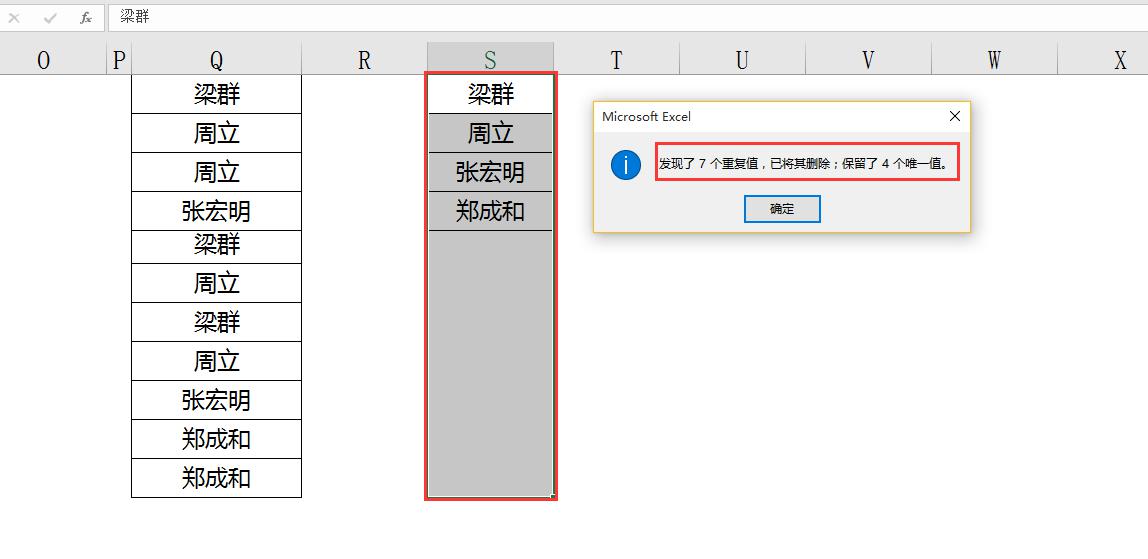
(2)再进行统计唯一值人数数量
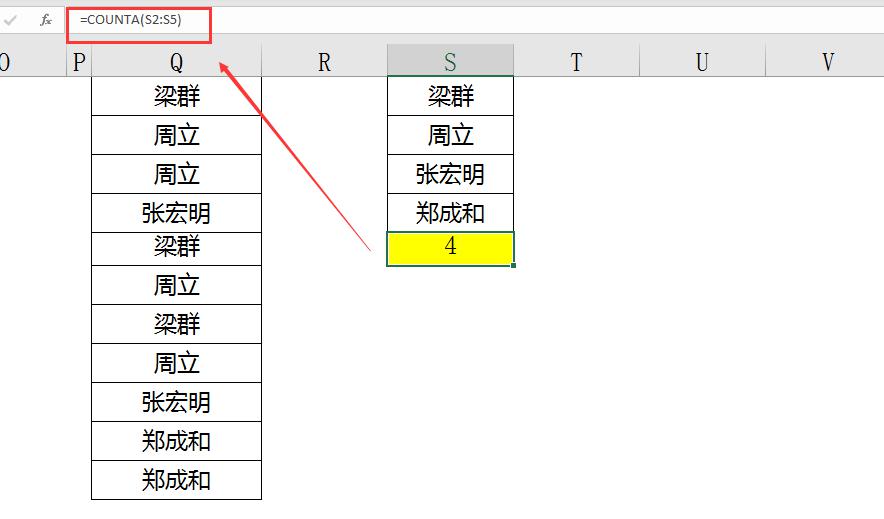
在删除重复项后,使用COUNTA函数统计剩余的唯一值数量,输入公式=COUNTA(S2:S5),即可得到不重复名字的个数。
场景二:统计单行中不重复名字的个数
如图:要求:求一年中每楼盘销售冠军各有多少人?

当需要统计一行中不同名字(如一年中各楼盘销售冠军)的个数时,由于数据量可能较大,直接删除重复项的方法可能不够高效。此时,可以利用COUNTIF函数结合数组公式的技巧来实现:
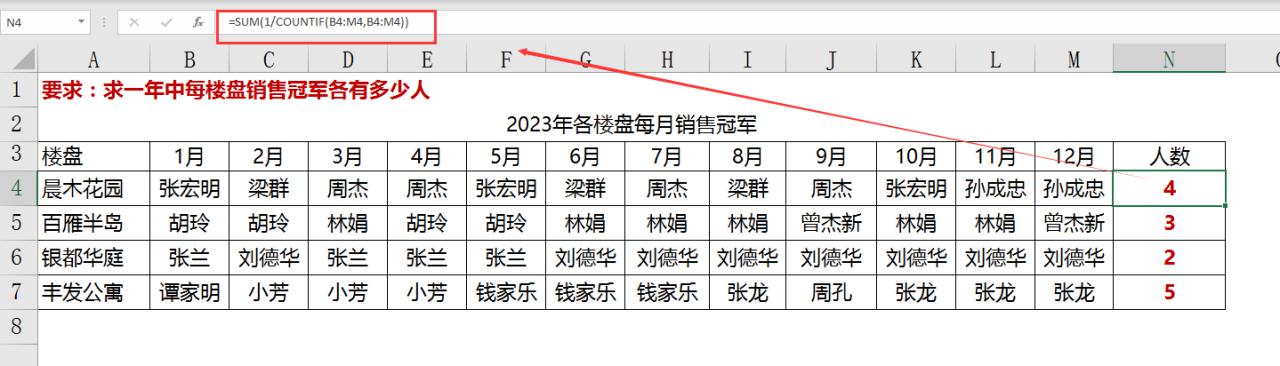
只需输入公式=SUM(1/COUNTIF(B4:M4,B4:M4))
我们分析一下公式:
先看一下简单的例子:比如有一列字母
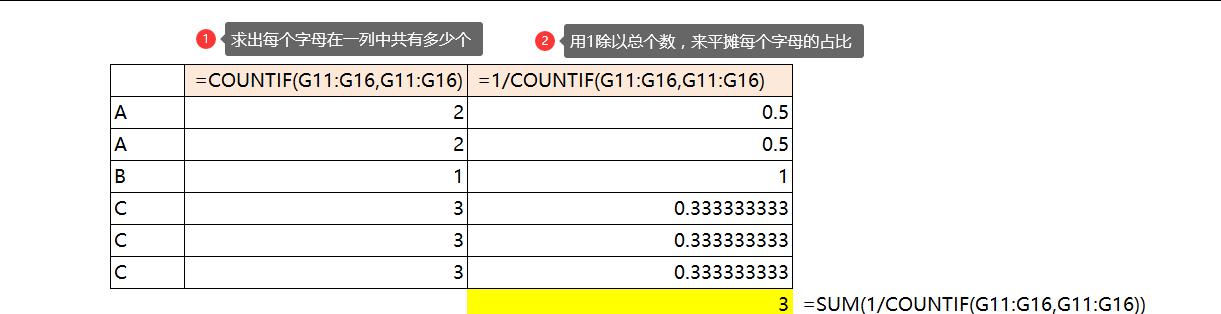
(1)COUNTIF(G11:G16,G11:G16),求出一列字母每个字母的总个数
(2)1/COUNTIF(G11:G16,G11:G16),求出每个字母的占比率
(3)SUM(1/COUNTIF(G11:G16,G11:G16)),结果即为不重复名字的个数。
根据行的这个计算过程,一年中各楼盘销售冠军的个数时,只是把列改行就可以。
场景三:统计不同类别不同产品的不重复数
当需要统计的数据涉及多个条件(如不同类别下的不同产品)时,可以使用COUNTIFS函数结合类似的方法来计算不重复数。
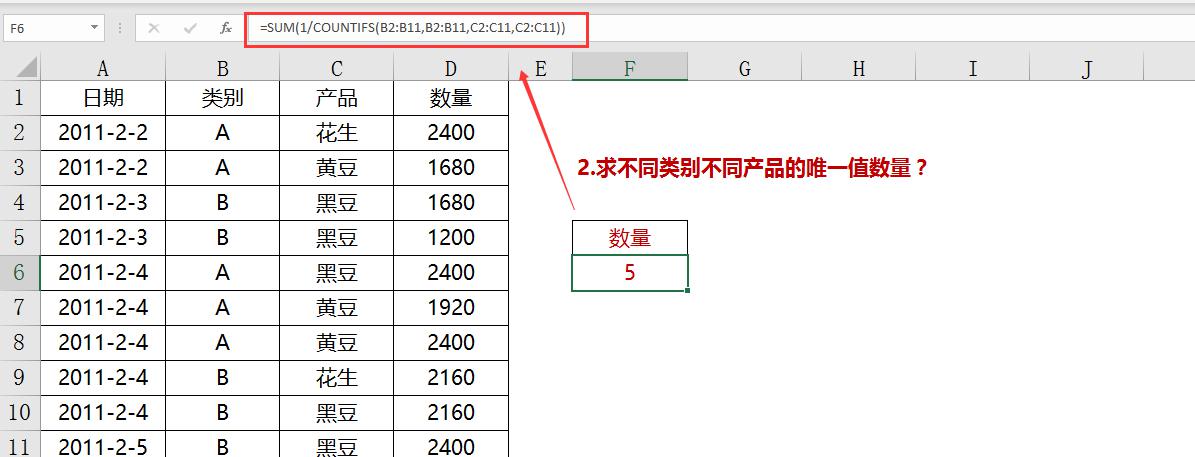
使用公式:在空白单元格中输入=SUM(1/COUNTIFS(B2:B11,B2:B11,C2:C11,C2:C11))。
这个公式中:
(1)COUNTIFS函数根据两个条件(类别和产品)来统计每个组合的出现次数。比起单列求重复值,这里它只需要再增加一个条件。
(2)通过1/COUNTIFS(B2:B11,B2:B11,C2:C11,C2:C11)计算每个组合的倒数,
(3)并用SUM函数求和,得到的结果即为满足两个条件组合下的不重复数。
通过以上方法,无论是单列、单行还是多条件的数据统计,都能高效地计算出唯一值的数量。








评论 (0)