
今天用一个案例,教大家学习 text 函数家族中几个比较特殊的成员。
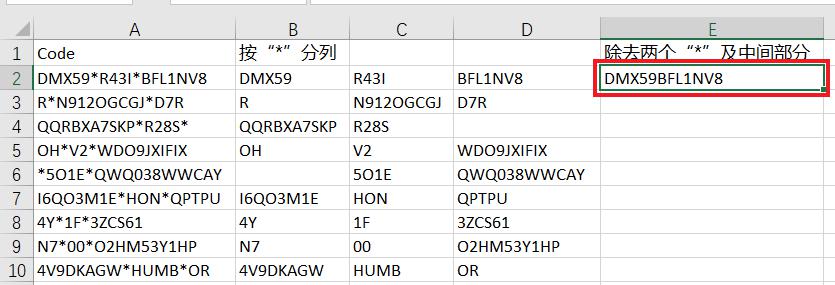
excel中如何 批量删除两个特定字符之间的内容?将下图 1 中的字符串分别按以下方式分隔、提取出来:
- 以“*”为分隔符,按列拆分;
- 将两个“*”及中间的所有内容删除
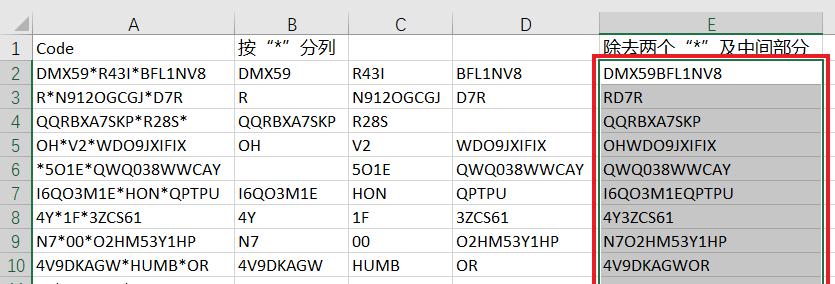
效果如下图 2 所示。

01 以“*”为节点,按列拆分
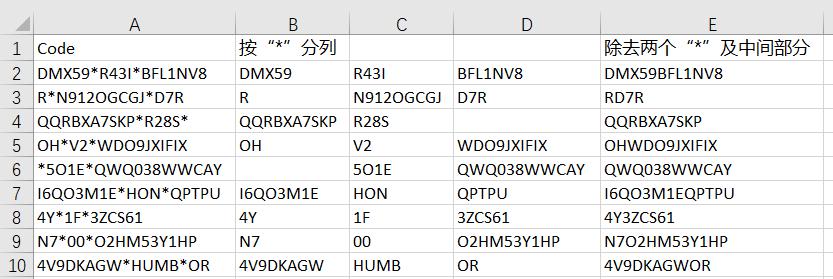
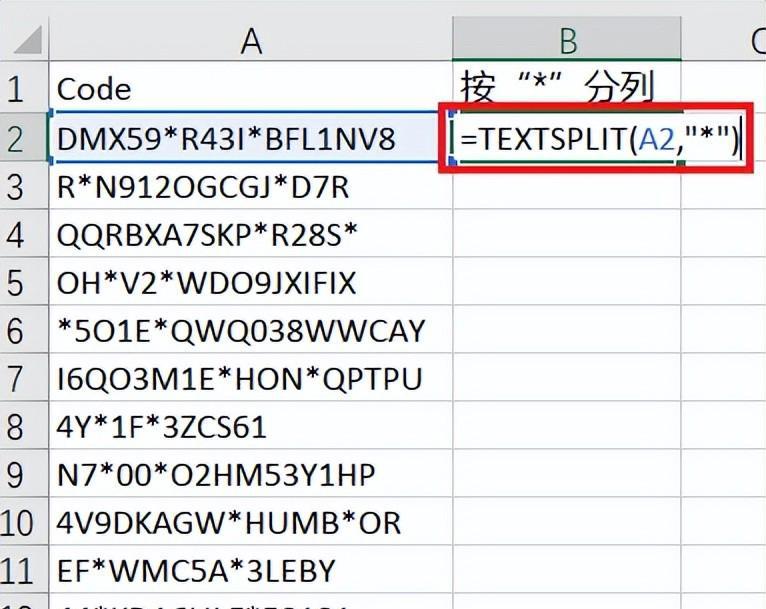
1. 在 B2 单元格中输入以下公式 --> 下拉复制公式:
=TEXTSPLIT(A2,"*")
公式释义:
- textsplit 函数顾名思义,作用就是使用列和行分隔符拆分文本字符串;
- 语法为 TEXTSPLIT(text,col_delimiter,[row_delimiter],[ignore_empty], [match_mode], [pad_with])
- 参数如下:
- text:必需,要拆分的文本;
- col_delimiter:必需,跨列溢出文本的文本分隔点;
- [row_delimiter]:可选,跨行溢出文本的文本分隔点;
- [ignore_empty]:可选,如果为 TRUE 则可以忽略连续分隔符;默认值为 FALSE,会创建一个空单元格;
- [match_mode]:可选,如果设置为 1 则可以不区分大小写;默认值为 0,区分大小写;
- [pad_with]:可选,用于填充结果的值,默认值为 #N/A。
- 公式的意思是将 A2 单元格的值以“*”为分隔符,拆分到不同的列中。

02 删除两个“*”及其中间的内容
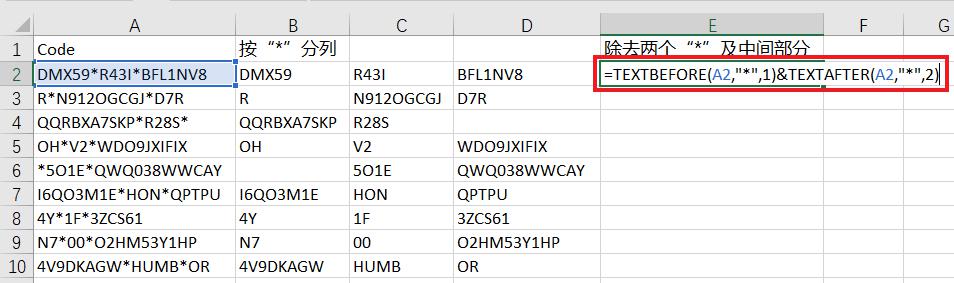
1. 在 E2 单元格中输入以下公式 --> 下拉复制公式:
=TEXTBEFORE(A2,"*",1)&TEXTAFTER(A2,"*",2)
公式释义:
- TEXTBEFORE(A2,"*",1):
- textbefore 函数的作用返回在给定字符或字符串之前发生的文本;
- 语法为 TEXTBEFORE(text,delimiter,[instance_num], [match_mode], [match_end], [if_not_found]);参数如下:
- text:必需,要查询的文本;不允许使用通配符;如果为空字符串,则返回空文本;
- delimiter:必需,标记要提取其前面内容的文本分隔点;
- [instance_num]:可选,分隔符在文本中出现的次数;默认情况下,instance_num = 1;负数开始从末尾开始搜索文本;
- [match_mode]:可选,否区分大小写,0 表示区分,1 不区分;默认为区分大小写;
- [match_end]:可选,将文本结尾视为分隔符;默认情况下,文本完全匹配;0 表示不将分隔符与文本末尾匹配;1 表示将分隔符与文本末尾匹配;
- [if_not_found]:可选,未找到匹配项时返回的值;默认情况下,返回 #N/A;
- 本公式表示从 A2 单元格中提取出第一个“*”前的所有内容;
- TEXTAFTER(A2,"*",2):
- textafter 与 textbefore 的语法基本相同,只是作用正好想法,是用于提取分隔符后面的内容;
- 从 A2 单元格中提取出第二个“*”后面的所有内容;
- &:最后再用连接符号将两个公式结果连接起来,就得到最终结果。








评论 (0)