
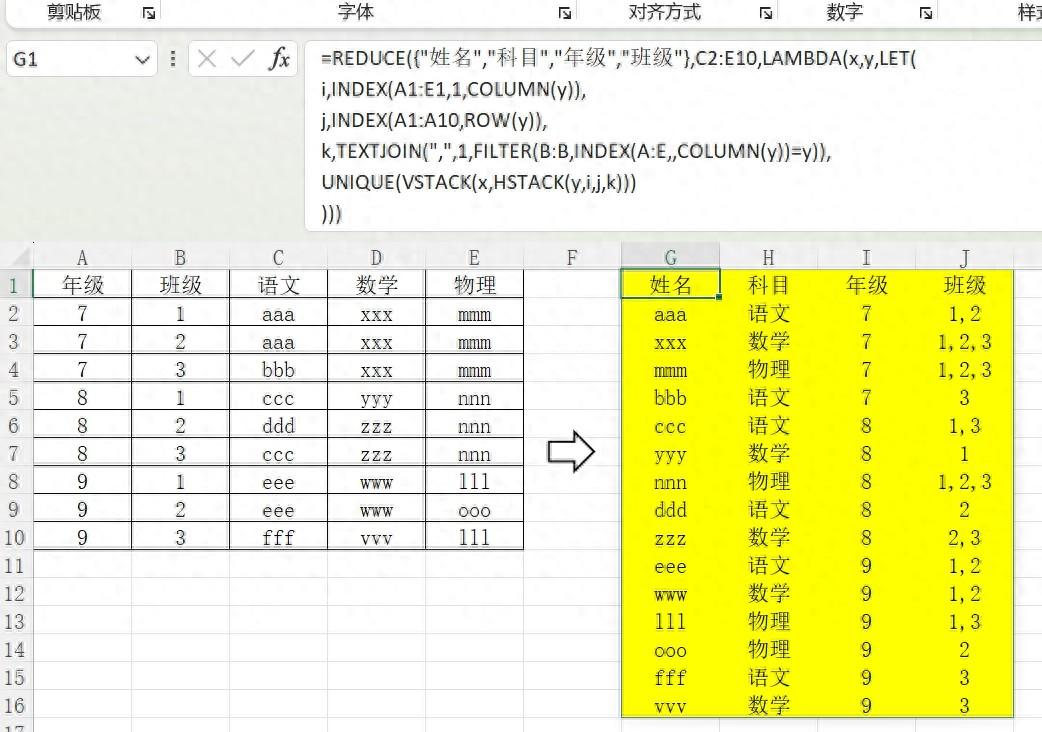
如图A:E列为数据源,字段由年级、班级、学科组成,想要将这些数据转换成G:J列的形式,即字段由姓名、科目、年级、班级组成的表格,公式如下:
=REDUCE({"姓名","科目","年级","班级"},C2:E10,LAMBDA(x,y,LET(
i,INDEX(A1:E1,1,COLUMN(y)),
j,INDEX(A1:A10,ROW(y)),
k,TEXTJOIN(",",1,FILTER(B:B,INDEX(A:E,,COLUMN(y))=y)),
UNIQUE(VSTACK(x,HSTACK(y,i,j,k)))
)))
公式思路:表格形式的转换我们一般叫它数据切片,即从数据中根据要求切下一部分的意思。
本例公式的主题由reduce(vstack(hstack……构成,hstack的主要作用是将需求字段的数据合并成一行,vstack的作用是提取累积器里的所有数据。reduce提供了遍历用的数组,就是源表中老师名字的部分。
由于提供的数组有重复部分,所以最后要用unique,也就是这句UNIQUE(VSTACK(x,HSTACK(y,i,j,k))),将重复数据过滤。
变量i,j,k分别提取了科目名称、年级、合并后的班级。在获取数据过程中使用了index,column,row函数,这是本例的一个亮点。它利用的reduce函数在遍历单元格数组时保留单元格行列索引属性的特点实现的。它大大简化了数据提取过程中繁琐的位置确定。当然它只对单元格数组起作用,对于内存数组就不行了,比如为了去重我们把C2:E10变为unique(tocol(c2:e10)),去重后的数组变简单啦,但已经变成了内存数组,就不能使用行列索引啦。这样后期处理起来反而复杂,我贴出内存数组遍历的公式,大家感受一下:
=REDUCE({"姓名","科目","年级","班级"},UNIQUE(TOCOL(C2:E10,,1)),LAMBDA(x,y,LET(
i,CONCAT(IF(ISNUMBER(FIND(y,MAP(C2:E2,LAMBDA(m,CONCAT(OFFSET(m,,,9)))))),C1:E1,"")),
h,ISNUMBER(FIND(y,MAP(C2:C10,LAMBDA(m,CONCAT(OFFSET(m,,,,3)))))),
j,UNIQUE(FILTER(A2:A10,h)),
k,TEXTJOIN(",",1,FILTER(B2:B10,h)),
r,VSTACK(x,HSTACK(y,i,j,k)),
r
)))




评论 (0)