

reduce函数是lambda函数类的集大成者,学会它基本掌握了循环类lambda的精髓,它可以以替代mapscanbyrowbycol等函数,从而减少需要记忆函数的数量。
参数一:初始数组。指定初始的数组,对于数值累加,一般设定为0,对于循环递归,一般设定为最早的数据。

其它一般设定为空值,最后再用drop去掉。
参数二:需要遍历的数组,一般是操作对象,同时配合offset可以关联更多的操作对象。也可以不是操作对象,仅仅是循环次数。
如,求10连续加10个1的和,公式为
=REDUCE(10,SEQUENCE(10),LAMBDA(X,Y,SUM(X) 1)),结果为20,变量y的作用仅为控制SUM(X) 1执行的次数。
参数三:函数体,由lambda变量及计算部分组成,能够完成各种各样的计算或者结果输出。
优点:
1、基本实现了循环的所有的功能,使函数的操作向编程迈进坚实一步。
2、功能非常全面,看似是累加器函数,实际上基本可以实现函数的所有功能,很多功能还在开发中。
3、实现整体表格的输出,不同于以前只能形成几个数据再拖动形成表格中的一部分,reduce函数配合vsatck和hstack实现了自定义表格的功能。
缺点:
1、复杂,需要很好的理解各部的作用,特别是lambda内表达式的使用。
2、繁琐,如初始值很多时候没有作用还需要用drop去掉,lambda变量自定义很多时候都一样但不能简化。
3、有用的配合类函数缺少,如reduce就是为了大规模数据才用的,但数据规模上来后对于数据的概要性函数应该补上。
4、对于错误值的处理方式过于简单,基本就是整个函数返回错误值,要知道可能只是好几千行结果里的几行出现问题。
- 功能:
1、累加,形成数组最后的累加值,配合vstack可以形成过程累加值,这样就与scan函数功能相同。
示例:=REDUCE(,{1,2,3,4},LAMBDA(x,y,VSTACK(x,TAKE(x,-1) y))),结果为1,3,6,10。
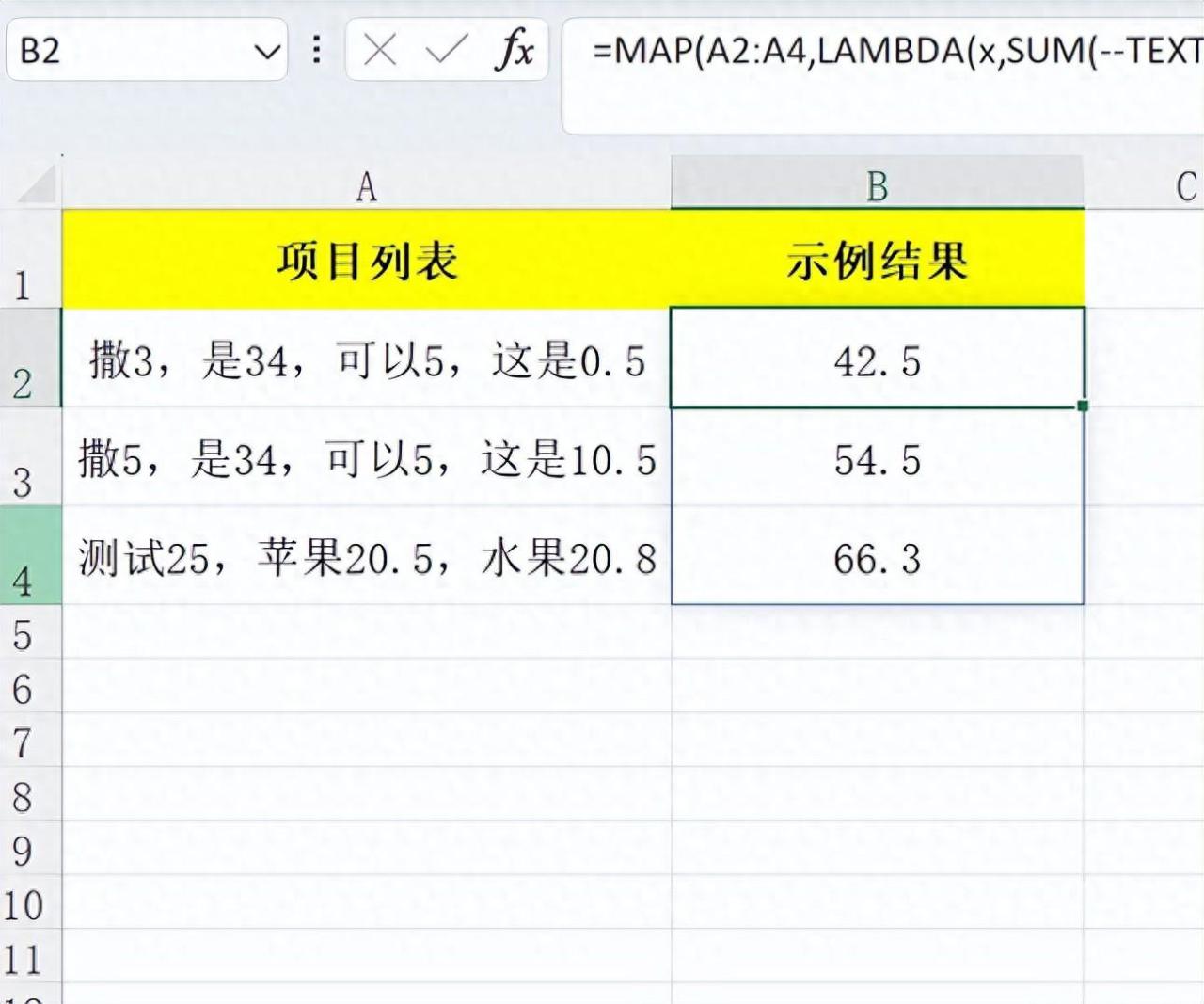
2、加速函数的运算过程,节省书写过程,如substitute函数的递归套用,filter函数的多值调用,这与map的功能产生的重叠。xlookup函数的多值调用及多值返回等。
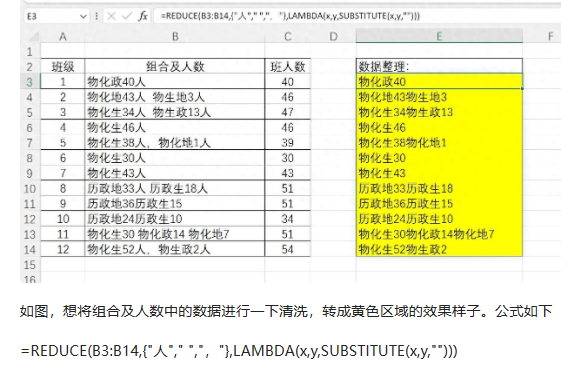
3、输出整个表单,配合vstack和hstack函数完成新格的输出,可以一次输出多个表格。

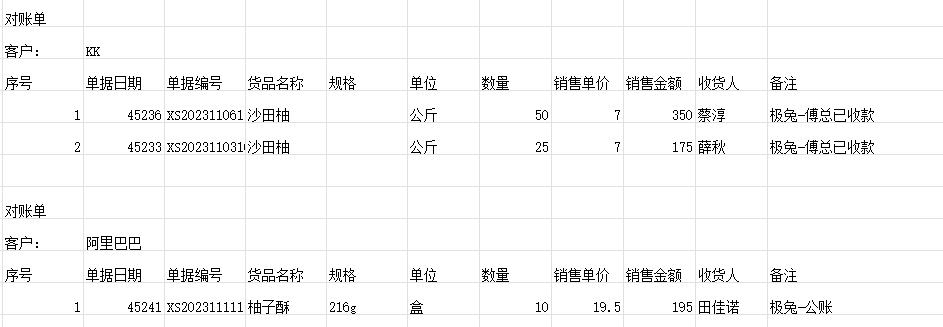
由明细生成对账单:
=IFERROR(REDUCE("",UNIQUE(明细!B4:B20),LAMBDA(x,y,VSTACK(x,VSTACK("",A4:K4,HSTACK(A5,y),A6:K6,HSTACK(SEQUENCE(ROWS(FILTER(HSTACK(明细!C4:J20,明细!O4:P20),明细!B4:B20=y))),FILTER(HSTACK(明细!C4:J20,明细!O4:P20),明细!B4:B20=y)))))),"")
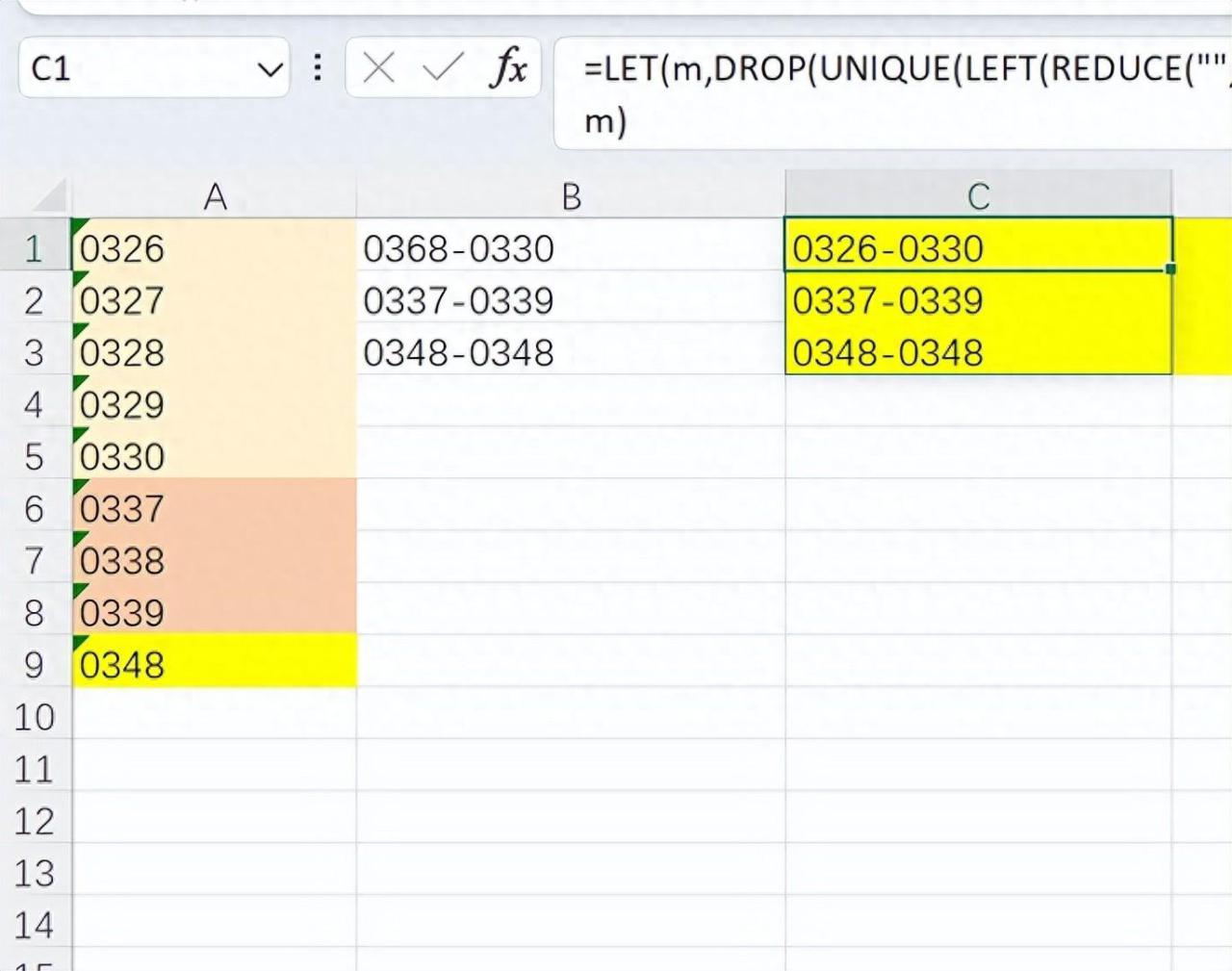
4、逆透视,根据要求形成新的切片。主要是数据的提取及位置变换方面。
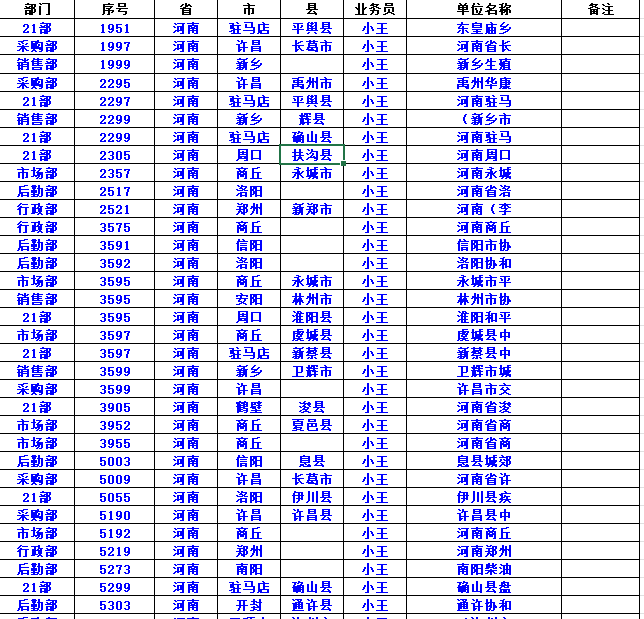
原数据按部门分类自动按每页30行进行分页打印,并在打印时内容不满30行时,页面空白的位置能否按格式自动填充网格至30行。
| =REDUCE(原数据!A1:H1,UNIQUE(原数据!A2:A109),LAMBDA(x,y,VSTACK(x,LET(i,FILTER(原数据!$A$2:$H$109,原数据!A2:A109=y,""),IF(ROWS(i)<30,VSTACK(i,EXPAND(" ",30-ROWS(i),8," ")),i))))) |
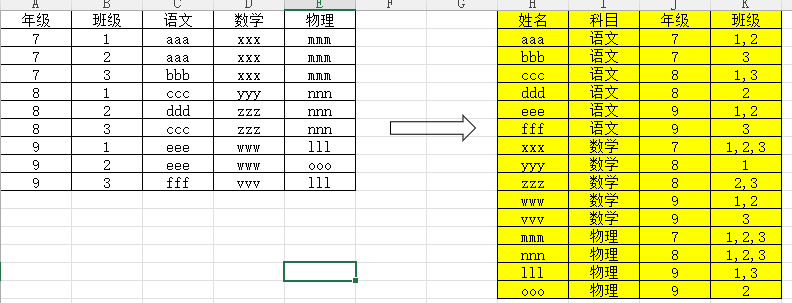
将源数据表格转换成右图的表格
=REDUCE({"姓名","科目","年级","班级"},C2:E10,LAMBDA(x,y,LET(
i,INDEX(A1:E1,1,COLUMN(y)),
j,INDEX(A1:A10,ROW(y)),
k,TEXTJOIN(",",1,FILTER(B:B,INDEX(A:E,,COLUMN(y))=y)),
UNIQUE(VSTACK(x,HSTACK(y,i,j,k)))
)))
5、配合offset函数操作行、列、一个区域的表格区域进行运算,形成相要的结果。

=REDUCE(A1:Q1,M2,LAMBDA(x,y,VSTACK(x,IF(y=22,IFS(COLUMN(A:Q)=13,U3:U7,COLUMN(A:Q)=17,Q2*V3:V7,TRUE,OFFSET(y,,-12,,16)),""))))
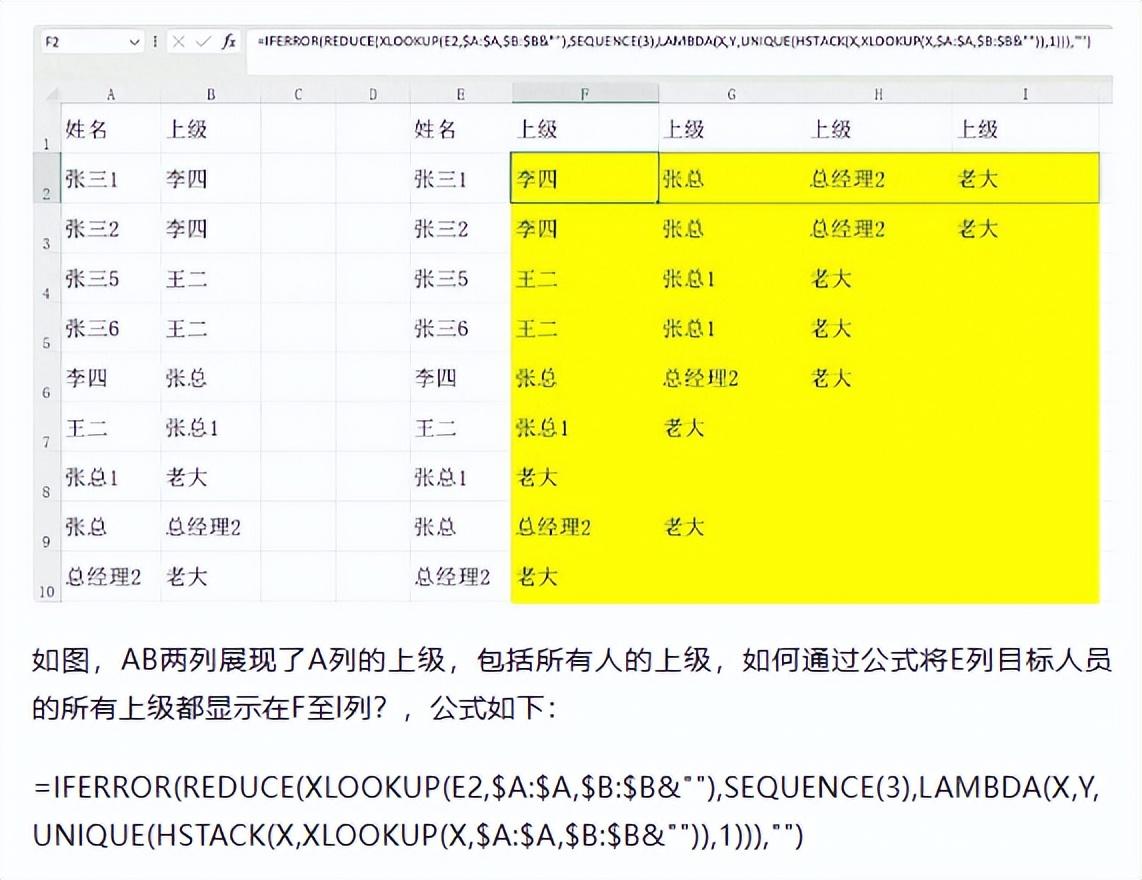
6、BOM父子级关系的处理,寻找所有的管理子级。







评论 (0)