
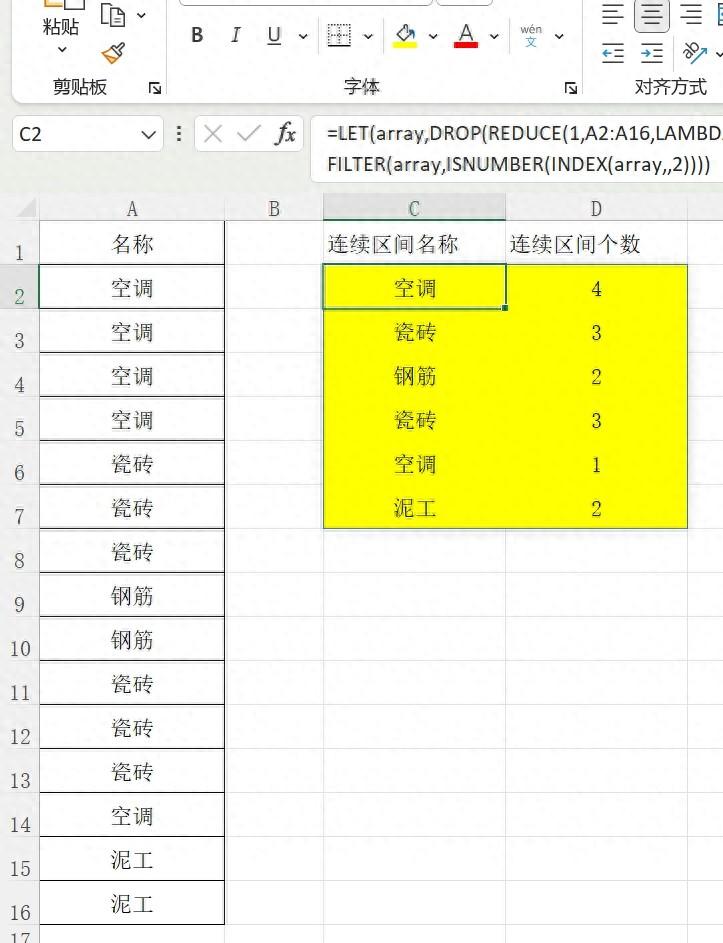
如图,A列为源数据,是装修材料的名称,出现顺序没有排序,可能一次性连续出现,也可能全部分分散,不连续的出现,还有可能只有一个,只出现一次,现在想统计每一个连续的名称在连续区域中出现的次数,如空调,在A2:A5单元格中连续出现了4次。公式如下:
=LET(array,DROP(REDUCE(1,A2:A16,LAMBDA(x,y,VSTACK(x,IF(y=OFFSET(y,1,),TAKE(x,-1,1) 1,VSTACK(HSTACK(y,TAKE(x,-1,1)),1))))),-1),
FILTER(array,ISNUMBER(INDEX(array,,2))))
公式思路:本公式的核心是array变量的计算。
计算主体对A2至A16单元格逐个与下一个单元格进行比对,如果与下一个单元格相同,则让累加器的最后一行、第一列加上1,如果不相同,则形成一个二行二列的二维数组:
| 空调 | 4 |
| 1 | #N/A |
这样即得到了泥工在连续区域的数量,又在最后一行,第一列得到一个1,以便下一次计算时用TAKE(x,-1,1)提取。
vstack(x,……)便得到一个数组:
| 1 | #N/A |
| 2 | #N/A |
| 3 | #N/A |
| 4 | #N/A |
| 空调 | 4 |
| 1 | #N/A |
| 2 | #N/A |
| 3 | #N/A |
| 瓷砖 | 3 |
| 1 | #N/A |
| 2 | #N/A |
| 钢筋 | 2 |
| 1 | #N/A |
| 2 | #N/A |
| 3 | #N/A |
| 瓷砖 | 3 |
| 1 | #N/A |
| 空调 | 1 |
| 1 | #N/A |
| 2 | #N/A |
| 泥工 | 2 |
数组里已经完成了对连续区域的统计,但还有些过程数据需要过滤掉,所以最后使用filter函数过滤不需要的过程数据。
本例还有初始值1的使用,正好可以弥补计数公式与实际数量之间的误差,因为4个单元格进行比较最多得到3个相同的结果。







评论 (0)